
In this article, we will see what Kafka Log Compaction is, how it works, and what is its use cases. In Kafka, we know that we can delete old messages in topics due to their size or age. Log Compaction is the third option here in addition. First, Let's see how Kafka itself describes Log Compaction:
Log compaction ensures that Kafka will always retain at least the last known value for each message key within the log of data for a single topic partition.
So, Kafka deletes old records if a newer version of the message has the same key in the partition log. If that is the case, why is it "at least the last known value" rather than "only the last value"? We will see the reason later in the blog post.
When a log is compacted, it splits into two sections: head and tail. The head is a standard log. When a new message comes to head, the message will append to the end. The tail is where the compaction occurs. Unlike the tail, the head can have duplicate keys. This is what Log Compaction basically is:

After the compaction, the order and offsets of the messages do not change. If we want to get a deleted record by its offset, Kafka will return the following message in the partition.
Note that we can set a Log Compaction retention policy per topic.
Log Compaction does not just remove duplicate messages. It also eliminates messages that have null value in their body. These messages are called tombstones.
We can delay this messages' removal with the
delete.retention.msconfig.
Now let's dive deeper into how Log Compaction works.
Segments
If we go from top to bottom:
- Kafka Topic has a log.
- The log has partitions.
- Partitions have segments.
- Segments have messages.
Segments are files which names end with ".log". Here is what a segment looks like:
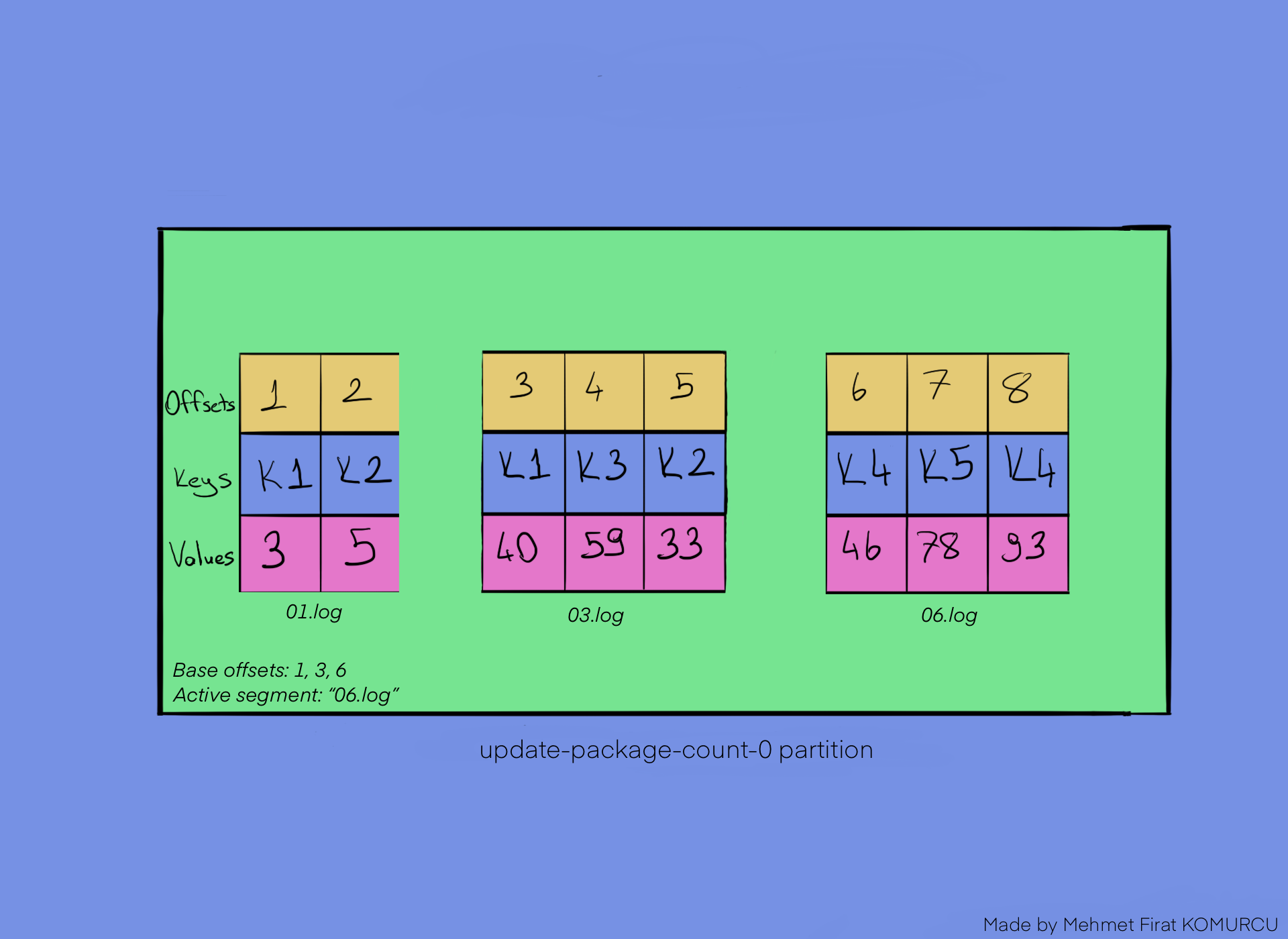
The first offset of a segment is called base offset. The segment file name consists of the base offset, like in "01.log" in the picture above.
The last segment of a partition is called active segment. New messages append to the active segment only. While Log Compaction occurs, the active segment is omitted. Therefore we can see duplicate messages in the active segment.
We can create new segments with two options: segment.bytes and segment.ms.
segment.bytes: create a new segment when the file size gets more significant than the parameter value.
segment.ms: create a new segment when the segment gets older than the parameter value.
Log Cleaners
Log Cleaners are those who process the Log Compaction. Log Cleaners are a pool of background threads.
Log Cleaner scans the logs and finds the dirtiest log. The dirtiest log can be calculated by the number of bytes in the head vs. bytes in the log. (head / (head + total)). this ratio is called the dirty ratio.
If the ratio is greater than
min.cleanable.dirty.ratio, then Log Cleaner will begin to compact the log. The default value of the config is 0.5.
Log Cleaner will exclude some segments from compaction. The first one is the active segment. That is why we can see duplicate messages in compacted logs.
The other segments are the segments that have messages younger than the
min.compaction.lag.msconfig value. The default value of the config is 0.
Log Cleaner creates a map that holds keys of records that are in the head. The map consists of the key and its offset. This map is called offset map. If the key is duplicated, the last offset will be the value. Log Cleaner uses the map for finding duplications in the partition.
Log Cleaner starts to scan segments, creates a copy of the segment, removes duplicate messages, and replaces the original segment with the new segment with non-duplicate messages. So Kafka does not need to copy the whole partition for compaction. Only one additional segment is sufficient.
This whole compaction process is done in the background periodically. Therefore, cleaning does not block consumer reads and I/O throughput.
Use Cases
As you read in this blog post, we can say that Log Compaction is a special kind of policy, and it can meet the needs of some cases. For example, caching solutions; compacted topics store only the last version of messages, making a great solution candidate. Backup Scenarios; after an app crash, the app can reload data with compacted topics. You can read for more uses cases in Bartosz Mikulski's blog post.
Conclusion
In this blog post, I've shown you what Log Compaction is, how logs are structured and how the compaction process works under the hood. You can check official documents and Sayed Mortaza's blog post for more details. Thank you for reading.
May the force be with you.




